The Complete Map of Generative AI: Understanding the 8 Layers and 4 Dimensions
Table of Contents
Introduction: Why You Need a Map, Not Just a Road Trip
If you've been tracking Generative AI (GenAI) over the last few years, you've likely noticed two things: GenAI has become incredibly important, and it is growing at an almost impossible pace. New terms, tools, and architectures surface constantly, often making it feel impossible to define a clear learning path or curriculum. Even seasoned educators and professionals admit they struggle to keep up.
The core issue is often a lack of an overall mental model—a "map". Think of it this way: if you want to find the best road from Point A to Point B, you first need a comprehensive map of the entire city to compare your routes.
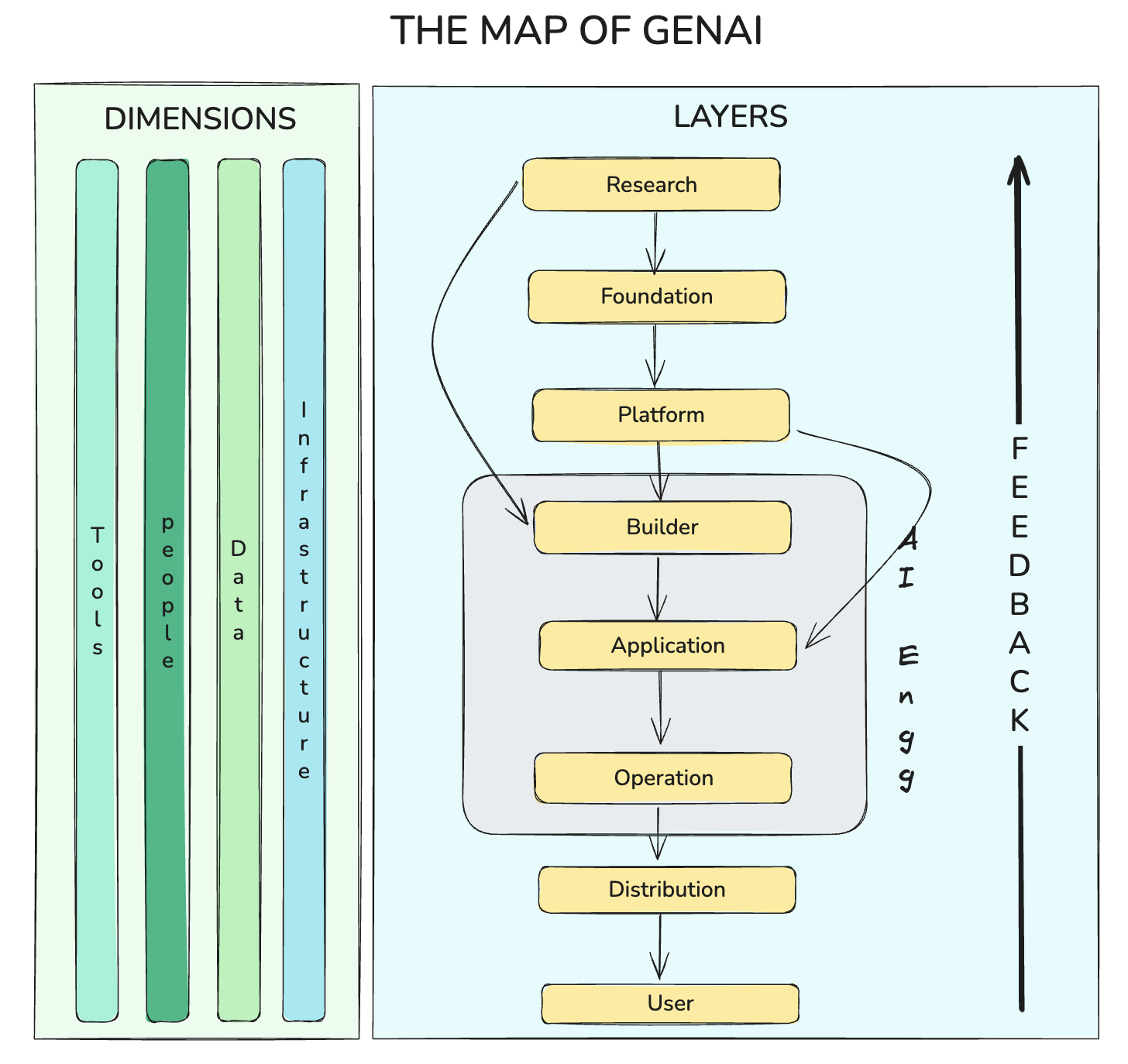
This post delivers that foundational map. Based on 30 days of focused effort to organize the GenAI chaos, we are sharing a conceptual framework that divides the entire GenAI landscape into 8 interconnected Layers and 4 enabling Dimensions.
By the end of this journey, you will gain a complete picture of GenAI. You will be able to fit any new term onto this map, locate yourself within the ecosystem, and finally, feel truly literate and confident about the future of AI.
The 8 Vertical Layers: Following the AI Life Cycle
The GenAI process is best understood as a lifecycle, where innovation flows from research and ultimately reaches the end-user. These layers operate like a sophisticated manufacturing supply chain, taking a raw idea and turning it into a deployable product.
Layer 1: The Research Layer (The Birthplace of Core Innovations)
The Research Layer is the birthplace of core AI innovations. It is here that raw concepts or ideas are refined before moving on to become concrete products.
What Happens Here: Ideas and concepts are refined, eventually leading to the core AI features we use today.
Who Works Here: Researchers in academic institutions (like MIT or Stanford) and private research labs (like Google Brain or OpenAI Research).
Key Focus Areas:
- New Model Architectures: Developing neural networks (e.g., the Transformer architecture) to solve flaws found in older models (like RNNs/LSTMs)
- Optimization Techniques: Finding ways to train increasingly large models faster, cheaper, and more reliably (e.g., Mixed Precision Training)
- Alignment: Developing techniques (like RLHF or DPO) to ensure models align with human values and understand which questions to answer safely
- Emergent Phenomena: Studying unexpected, surprising capabilities that emerge when models are trained at massive scales, such as step-by-step reasoning or advanced calculation abilities
Output: Research Papers (like "Attention Is All You Need"), standardized Datasets, and Benchmarks.
Layer 2: The Foundation Layer (The Factory Floor)
The Foundation Layer is the manufacturing unit of the map. It takes successful research ideas and converts them into large-scale, working AI models.
Purpose: To train, align, and fine-tune powerful foundation models that others can utilize.
Who Works Here: Applied Scientists, Data Scientists, and ML Engineers in big tech labs (due to the immense cost and compute required).
Key Focus Areas:
- Data Preparation: Curating massive, high-quality, diverse, and clean datasets (like Common Crawl) to ensure the model has comprehensive world knowledge
- Model Implementation: Translating the theoretical architecture into executable code, finalizing model topology, scale (parameters/layers), and incorporating optimization settings
- Distributed Training: Using specialized GPU/TPU Superclusters and distributed systems (like Megatron-PyTorch) to train models in parallel due to their massive size
- Evaluation: Checking model performance against established benchmarks like GLUE (Natural Language Understanding) or GSM 8K (Reasoning) before deployment
Output: Base models, Aligned models, and Fine-tuned models (e.g., specialized coding or medical models).
Layer 3: The Platform Layer (The API Gateway)
This layer acts as the primary distribution channel for the trained foundation models. It is responsible for making these models usable by developers worldwide.
What Happens Here: Foundation models are brought online.
Purpose: To provide easy, reliable, and scalable access to Foundation models through APIs and tools.
Who Works Here: Platform engineers, API developers, MLOps specialists, and Cloud architects.
Key Delivery Modes:
- Model APIs: Accessing proprietary, closed-source models (like OpenAI's GPT models) through HTTP requests without downloading the weights
- Cloud AI Platforms: Used by large companies, these platforms (like AWS Bedrock or Azure AI Foundry) install foundation models on the company's private cloud infrastructure to guarantee data security and prevent data from leaving the company's environment
- Self-Hosted Models: Tools (like Ollama) that allow users to download open-source model weights onto their own machine
- Hosting & Acceleration Services: Companies (like Replicate) that host open-source models on powerful servers and provide API access, catering to users whose hardware is restricted
Key Focus Areas: Model Serving (loading weights into GPU memory for inference), Inference Optimization (speeding up response time using techniques like batching or quantization), and Scalability Management (auto-scaling and load balancing).
Layer 4: The Builder Layer (The Logic and Orchestration)
The Builder Layer is where AI's core intelligence is enhanced and structured into intelligent workflows and systems. Raw foundation models are limited to next-word prediction; this layer adds logic, memory, and tool-use capabilities.
Who Works Here: AI Engineers, Prompt Designers, Framework Developers (e.g., LangChain/LangGraph creators).
Key Focus Areas (Enhancing AI Capabilities):
- Prompt Engineering: Crafting and testing prompt sequences (like Chain of Thought) to improve the model's reasoning and output quality
- RAG (Retrieval Augmented Generation): Techniques that allow the model to access and reason over private or external data sources (like an enterprise knowledge base) that it was not originally trained on
- Agentic AI: Building systems (agents) that can perform complex actions on behalf of the user, beyond simple conversation (e.g., using tools to book tickets or scrape the web) — see AI agents and agentic AI explained in depth
- Memory Management: Implementing short-term and long-term memory to ensure the model maintains conversational context across sessions (foundation models are stateless by default)
- Context Engineering: Managing the data fed into the model's context window, ensuring the relevant tools and information are present without exceeding limits
Output: Ideas, Techniques, and Frameworks/Libraries (such as LangChain, LangGraph, LlamaIndex). For a production implementation of these patterns, see Human-in-the-Loop patterns using LangGraph.
Layer 5: The Application Layer (Building End Products)
This layer uses the models and the builder frameworks to construct usable software for end-users.
Purpose: To build AI native and AI integrated software for users.
Who Works Here: AI Engineers, Full-Stack Developers, UI/UX Designers, and Product Managers.
The Two Types of AI Software:
- AI-Native Software: Products whose core selling point is AI itself (e.g., ChatGPT, Perplexity, Cursor IDE)
- AI-Integrated Software: Existing products where AI features are integrated to boost efficiency (e.g., Microsoft 365 Copilot, Canva AI, Adobe Firefly)
Key Focus Areas:
- Productization: Converting the AI logic (from the Builder Layer) into a fully functional product, including comprehensive system design, back-end development, and front-end UI/UX
- Safety & Alignment: Applying application-level guardrails (beyond the foundation model's alignment) to prevent misuse, such as blocking requests for private employee data within a company chatbot
- Performance Optimization: Ensuring the application works fast and efficiently at low cost, often through asynchronous programming and caching frequently asked questions
Layer 6: The Operation Layer (LLMOps and Reliability)
The Operation Layer is dedicated to deploying, monitoring, and managing AI systems once they are ready for production. This domain is often referred to as LLMOps.
Purpose: To keep AI systems stable, scalable, and continuously improving in real-world use.
Who Works Here: MLOps Engineers, DevOps Engineers, SREs (Site Reliability Engineers), and Observability Experts.
Key Focus Areas:
- Deployment: Packaging the application (e.g., using Docker and Kubernetes), setting up the cloud environment, and managing release strategies (like Canary deployments)
- Logging & Monitoring: Tracking system health and performance over time
- Logging (The Black Box): Recording detailed, event-level information about what has happened (for diagnosis, auditing, and forensics)
- Monitoring (The Pilot's Dashboard): Tracking aggregated metrics in real-time about what is happening and triggering alerts when thresholds are breached
- Evaluation: Performing continuous evaluation even after deployment to detect drift (where performance degrades over time due to changes in user behavior or silent model updates)
- Feedback: Using explicit (thumbs-up/down) and implicit (user behavior, like cutting an answer mid-way) signals to drive continuous improvement of the product
Output: Deployed AI products running reliably at scale.
Layer 7: The Distribution Layer (Growth and Market Reach)
This is the layer where the technical complexity of AI transforms into a business strategy. The goal shifts from building the product to scaling the user base and revenue.
What Happens Here: AI products reach users through channels, platforms, and marketplaces.
Who Works Here: Growth Engineers, Marketing Teams, and Product Managers.
Key Focus Areas:
- Delivery Channels: Reaching users through all available marketplaces (e.g., Apple App Store, Google Play, Slack Marketplace)
- Ecosystem Integration: Creating partnerships or integrations with large platforms (like Zapier or Slack) to penetrate existing user bases
- Strategic Partnerships: Collaborating with companies or governments to quickly gain massive user adoption
- Compliance & Localization: Adapting the product (e.g., local language support) and ensuring it adheres to regional legal and ethical rules (e.g., European Union's AI laws)
Output: Market reach, user adoption, and revenue growth.
Layer 8: The User Layer (The Final Destination)
The User Layer is the end of the line—where users interact with the deployed AI application.
Purpose: To create value for the user and gather insights and feedback that guide the continuous improvement of the entire AI system.
Who Exists Here: Daily users, professional users, domain-specific users (doctors, coders), Prompt Creators, and Educators.
Key Focus Areas:
- User Interaction: Enhancing UI/UX, enabling multi-modal communication (text, voice, image), and suggesting follow-up actions
- Personalization: Using memory features and user preferences to provide tailored responses
- Prompt Literacy: Educating users on how to write effective prompts, which can significantly alter the quality of the AI's response
- Trust & Ethics: Building user confidence through transparency, such as providing source citations (Perplexity) or allowing users to manage their privacy settings (ChatGPT)
Output: User data, preferences, behavioral data, and crucial feedback.
The Feedback Loop: The Engine of AI Progress
A critical insight of the GenAI Map is that the process is not strictly unidirectional (Research down to User). There is a constant, powerful Feedback Loop that flows from the User Layer back up to the Research Layer, constantly driving updates and innovation.
Analogy: The Systemic Hallucination Fix
Imagine a scenario where a user, trying to use a research chatbot, notices that the AI confidently produces fake citations—a systemic factuality problem (hallucination). Here's how the feedback loop addresses this:
Step 1 - Incident (User Layer): A researcher flags the fake citations via a thumbs-down button or note.
Step 2 - Escalation (Operation Layer): Monitoring dashboards detect thousands of similar reports. Since latency and token usage are normal, it's identified as a systemic factuality problem and escalated up the stack.
Step 3 - Quick Fix Attempt (Application Layer): The product team updates prompt templates and adds a "Verify sources" disclaimer. Improvement is limited, so the issue is escalated to the Builder Layer.
Step 4 - Root Cause Analysis (Builder Layer): Teams inspect RAG pipelines and model performance. They find the retriever works, but the model struggles with reasoning when presented with multiple contexts, indicating a deeper model flaw.
Step 5 - Developer Demand (Platform Layer): Engineers confirm an API-wide issue (high hallucination rate) and request a "factual mode" from the Foundation Layer.
Step 6 - Model Retraining (Foundation Layer): The root cause is identified: training rewarded fluency (sounding good), not truthfulness. The model is retrained with factual data and new signals, resulting in a release like GPT-4 Turbo (fewer hallucinations).
Step 7 - Innovation (Research Layer): Researchers realize that current models predict fluency, not truth. This discovery spurs new research directions, such as Direct Preference Optimization (DPO) and Retrieval Grounded Architectures, informing future models like GPT-5.
This loop demonstrates how user experience drives research, leading to a new cycle of improved models.
The 4 Horizontal Dimensions: The Enablers
While the Layers define the process flow, the four Dimensions are the enablers—the crucial resources required at every single layer to make AI function.
1. Infrastructure (The Hardware and Compute)
Infrastructure provides the physical and virtual machinery necessary for every task.
Foundation Layer: Requires GPU/TPU Superclusters, High-Speed Interconnects (like InfiniBand) for parallel data throughput, and Orchestration Systems (like Kubernetes/Ray) to schedule massive training jobs.
Platform Layer: Needs Inference Clusters (for low-latency serving), Model Hosting Infrastructure (Hugging Face Hub), and Load Balancers/CDNs (Cloudflare, AWS CloudFront) to handle global traffic.
Builder Layer: Relies on Vector Databases (Pinecone, Weaviate) for RAG systems, and lightweight Application Servers (FastAPI/Flask) for orchestration services.
Distribution Layer: Requires App Store Infrastructure, and Billing & Subscription Systems (Stripe) for API monetization.
2. Data (The Fuel and Feedback)
Data is not just training sets; it is any serialized information handled across the stack.
Research Layer: Uses Benchmark Datasets (ImageNet, GLUE) for evaluation, task-specific datasets, and Synthetic Data for controlled experimentation.
Foundation Layer: Requires Web-Scale Text Corpora (Common Crawl), Multimodal Data, and crucial Alignment Labels (human preference data for RLHF).
Builder Layer: Deals with Enterprise Knowledge Bases (wikis, internal docs), Vector Databases (semantic indexes), and Long-Term Memory Stores (previous agent state histories).
Operation Layer: Handles Telemetry Streams (logs of inference, latency, resource usage), User Feedback Data, and Evaluation Data (test sets for regression testing and drift detection).
3. Tools (The Software and Frameworks)
Tools are the software applications, libraries, and frameworks that automate and execute tasks at each layer.
Foundation Layer: Uses distribution and optimization frameworks like DeepSpeed or Megatron-PyTorch Lightning.
Platform Layer: Utilizes optimized inference engines (vLLM, TensorRT-LLM) and containerization tools (Docker, Kubernetes).
Application Layer: Integrates orchestration frameworks (LangChain, LangGraph, CrewAI) and web frameworks (Next.js, React) to build the front-end product.
Operation Layer: Includes observability tools (LangSmith, LangFuse) and monitoring software (Prometheus/Grafana).
4. People (The Human Talent)
Every layer requires specialized human expertise, creating diverse job roles across the GenAI economy.
Research/Foundation: AI Researchers, Mathematicians, Applied Scientists, and Distributed Systems Engineers.
Builder/Application: AI Engineers (designing reasoning chains and integrating builder logic), Prompt Engineers, and Product Managers.
Platform/Operation: MLOps/DevOps Engineers (handling scaling and serving), Security Experts, and Trust & Safety Teams (enforcing guardrails).
Distribution/User: Growth & Product Marketers, Developer Relations (DevRel) Teams, Sales Engineers, End Users, and Educators.
Key Takeaways and Creating Your Own Roadmap
The complexity of Generative AI is vast, but it is not random. By viewing it through the structured lens of 8 Layers and 4 Dimensions, we achieve a clarity that was previously lacking.
Now that you have this map, you can make your own road map.
Locate Yourself on the Map
If you are targeting AI Engineering: Your focus lies primarily in the Builder, Application, and Operation Layers. You must master the tools and techniques (like RAG and LLMOps) that convert models into reliable systems.
If you are a Business Leader or Startup Founder: Your primary concern should revolve around the Distribution and User Layers, ensuring market reach, compliance, user adoption, and monetization.
If you are focusing on Core Model Technology: Your expertise should center on the Research and Foundation Layers, dealing with model architectures, massive data curation, and training techniques.
This map gives you the power to judge any new development or curriculum. If someone presents a new AI tool, you know exactly which layer it belongs to and which role it serves. This knowledge is your foundation for success in the rapidly evolving world of GenAI.